17 Maximum-Likelihood
Bei der Herleitung der Gerade bei der einfachen linearen Regression wurde zunächst ein Kriterium angesetzt, die Minimierung der quadrierten Abweichungen der beobachteten Punkte \(Y_i\) von den auf der Gerade liegenden vorhergesagten Punkten \(\hat{Y}_i\), den Residuen. Bei diesem Ansatz sind zunächst keine statistischen Überlegungen notwendig gewesen. Anschließend im Rahmen der Inferenz zu den Modellparametern \(\beta_0\) und \(\beta_1\) wurde dann die Modellannahme der Normalverteilung der Residuen \(\epsilon_i \sim \mathbf{N}(0,\sigma^2)\) dazugenommen um eine statistische Analyse der Modellkoeffizienten und der statistischer Signifikanz bzw. Hypothesentestung einzuführen. Im folgenden wird eine alternative Herleitung entwickelt über die Maximum-Likelihood Methode. Diese Herleitung bildet dabei ein grundlegendes Verfahren, dass im Fall der linearen Regression zu den gleichen Ergebnissen kommt, aber einen allgemeineren Ansatz darstellt der dann auch im späteren Verlauf die Betrachtung von Modellen erlaubt die mit dem RMS Ansatz nicht möglich sind.
Tipp
Um den folgenden Inhalten einfacher folgen zu können, kann es sinnvoll sein, sich noch einmal kurz die Inhalte aus Anhang A aus den Abschnitten Logarithmus, Ableitungen und Extremwerte zu vergegenwärtigen.
17.1 Likelihood
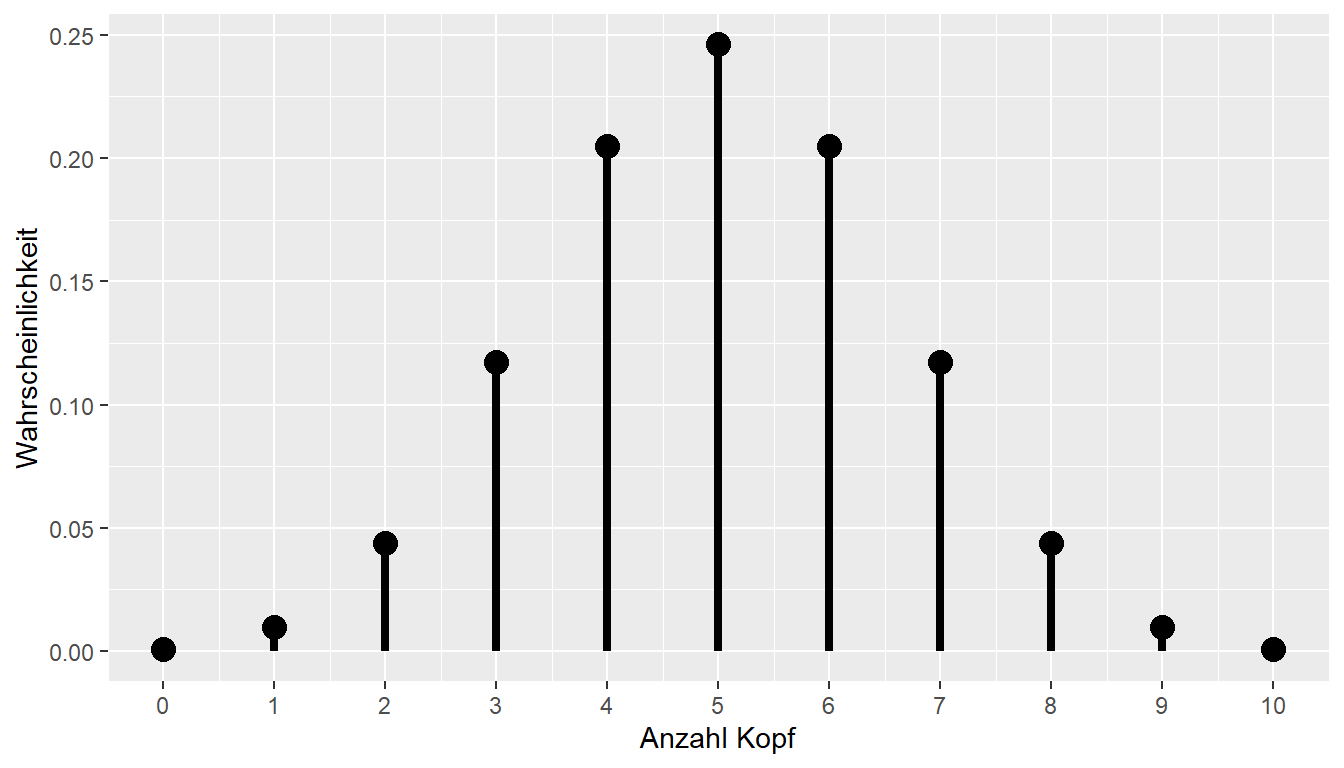
Im ersten Schritt muss zunächst der Begriff des Likelihood entwickelt werden. Die Likelihood ist eng mit dem Konzept der Dichte- bzw. Wahrscheinlichkeitsfunktion verbunden. Sei zum Beispiel der n-fache MÜnzwurfes betrachtet. Diese Experiment kann mit Hilfe der Binomialverteilung (siehe Gleichung 11.4) beschrieben werden.
\[ \text{Binom}(Y, N, p) = P(Y = y \mid N, p) = \binom{N}{y}p^y (1-p)^{N-y} = \binom{N}{y}p^y q^{N-y} \]
Hier ist \(Y\) die Anzahl der Köpfe, \(N\) die Anzahl der Würfe und \(p\) die Wahrscheinlichkeit bei einem Wurf Kopf zu beobachten. In Abbildung 17.1 ist die Binomialverteilung für den Fall \(N = 10, p = 0.05\) dargestellt.
Nun kann die Schreibweise \(\text{Binom}(Y,N,p)\) etwas umgeändert werden, wenn das Symbol für den Parameter \(p\) durch das Symbol \(\theta\) ersetzt wird. Dies hat inhaltlich keine Folgen, sondern ist lediglich eine Änderung der Schreibweise. Es folgt \(\text{Binom}(Y,N,p)=\text{Binom}(Y,N,\theta)\).
Seien nun die Daten \(y\) beobachtet worden. D.h. es wurde ein Münzexperiment, z.B. \(N = 10\)-mal durchgeführt worden und es wurde sechsmal Kopf beobachtet, d.h. \(y = 6\). Der unbekannte Parameter in \(\text{Binom}\) ist nun lediglich \(\theta\), da \(\text{Binom}(6, 10, \theta)\) gilt. Wird zunächst die Reihenfolge der Parameter nach \(\text{Binom}(\theta, 6, 10)\) geändert, kann dieser Ausdruck als Funktion von \(\theta\) interpretiert werden. Wenn nun noch die Werte \(y = 6\) und \(N = 10\) als gegeben interpretiert werden, dann erhält man eine Funktion \(\text{Binom}(\theta)\). D.h. in Verbindung mit einem beobachteten Datensatz, durch den zwei der drei Parameter von \(\text{Binom}\) definiert werden, wird eine neue Funktion definiert, welche nur noch einen Parameter \(\theta\) besitzt. Dieser Parameter war ursprüngliche das \(p\), die Wahrscheinlichkeit Kopf bei einem Wurf zu beobachten, wird nun aber mit dem Symbol \(\theta\) bezeichnet.
Diese Umbenennung erscheint zunächst als überflüssige Arbeit, hilft im weiteren Verlauf, da beispielsweise in der Literatur die Konvention herrscht den freien Parameter einer Likelihood-Funktion mit dem Symbol \(\theta\) zu bezeichnen. Wird nun noch eine weitere Umbenennung vorgenommen, und \(\text{Binom}\) durch das Symbol \(\mathcal{L}\) ersetzt, wird aus \(\text{Binom}(\theta) \equiv \mathcal{L}(\theta)\). Das stylisierte L in \(\mathcal{L}\) steht dann, entsprechend für Likelihood.
Die Likelihood-Funktion \(\mathcal{L}(\theta)\) kann nun entsprechend für verschiedene Wert von \(\theta\), im vorliegenden Fall \(p\) Kopf, abgetragen werden, wenn die beobachteten Daten \(y\) als gegeben angesehen werden. Konkret bedeutet dies zum Beispiel in R wo die Wahrscheinlichkeitsfunktion der Binomialverteilung mit dbinom() bezeichnet wird. Sei also nun \(N = 10\) und sechsmal Kopf beobachtet worden dann führt dies zum Beispiel für \(p = 0.5\) zu.
n_kopf <- 6
N <- 10
p_1 <- 0.5
dbinom(n_kopf, N, p_1)[1] 0.2050781D.h. dbinom() liefert die Antwort auf die Frage: “Was ist die Wahrscheinlichkeit sechsmal Kopf zu beobachten wenn die Wahrscheinlichkeit bei einem Wurf \(p = 0.5\) ist?
Als nächste könnte der Wert \(p = 0.4\) betrachtet werden. Dies führt analog zu dem folgenden Output führt:
p_2 <- 0.4
dbinom(n_kopf, N, p_2)[1] 0.1114767D.h. die Wahrscheinlichkeit sechsmal Kopf zu beobachten wenn die Wahrscheinlichkeit für Kopf bei einem Wurf \(p = 0.4\) ist, ist geringer als die Wahrscheinlichkeit bei \(p = 0.6\). Sei noch ein Wert, z.B. \(p = 0.75\), ausprobiert.
p_3 <- 0.75
dbinom(n_kopf, N, p_3)[1] 0.145998Hier ist die Wahrscheinlichkeit auch wieder geringer als bei \(p = 0.6\). D.h. es möglich mit Hilfe der Likelihood-Funktion \(\mathcal{L}(\theta)\) verschiedene Werte von \(\theta\) miteinander zu vergleichen und denjenigen zu bestimmen, der am plausibelsten unter den beobachteten Daten erscheint. Die Regel dabei ist immer, derjenige Wert von \(\theta\) der die höhere Likelihood generiert ist der plausiblere. Der nächste Schritt ist dementsprechend nicht nur einige wenige Wert für \(\theta\) auszuprobieren sondern systematisch alle Wert \(\theta\) zu testen. In Abbildung 17.2 ist die dementsprechend die Likelihood-Funktion \(\mathcal{L}(\theta)\) für Werte zwischen \(0\) und \(1\) für \(\theta\) abgetragen.
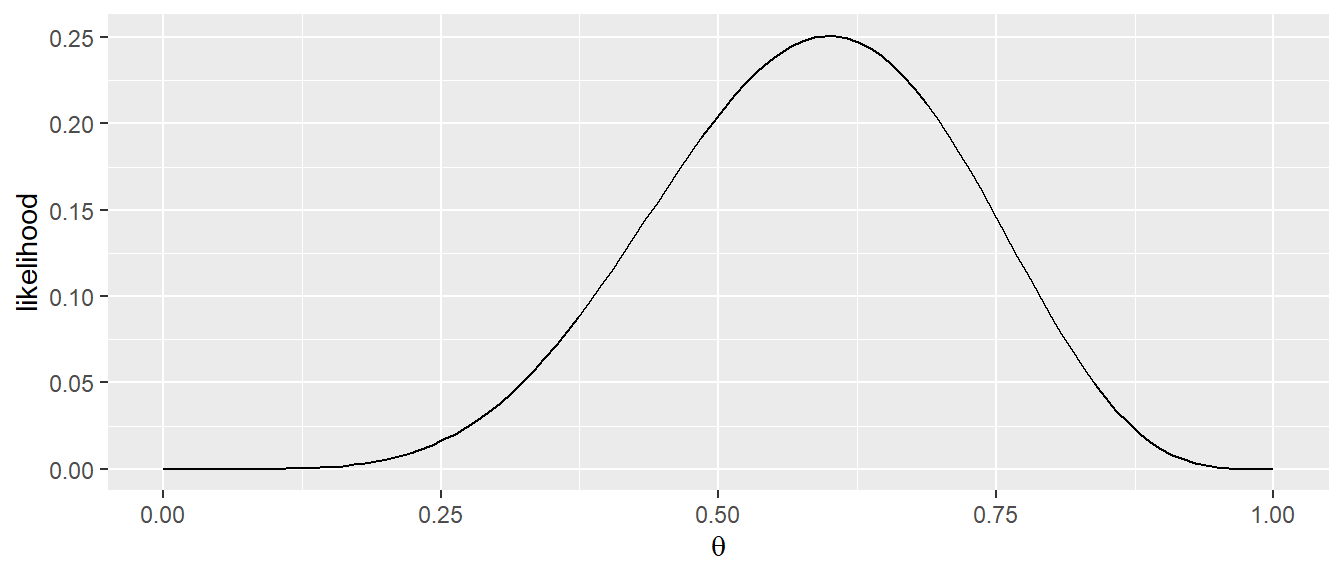
Zunächst fällt auf, dass im Unterschied zu Abbildung 17.1 der Graph in diesem Fall kontinuierlich ist. Die Wahrscheinlichkeitsfunktion der Binomialverteilung ist eine diskrete Funktion, da Wahrscheinlichkeiten für eine endliche Anzahl von Ausgängen (=Anzahl der Köpfe) berechnet werden. Im Gegensatz dazu, ist der Likelihood-Graph \(\mathcal{L}(\theta)\) kontinuierlich, da er eine Funktion von \(\theta\) ist, dass allerdings nur Werte im Bereich \(\theta \in [0,1]\) annehmen kann.
Der Likelihood-Graph ändert sich nun entsprechend, wenn ein anderes Ergebnis beobachtet wird. Seien zum Beispiel bei \(N = 10\) Würfen nur drei Köpfe (\(y = 3\)) beobachte worden ergibt sich der folgende Graph für \(\mathcal{L}(\theta)\) im Gegensatz zu dem ursprünglichen Graphen aus Abbildung 17.2:
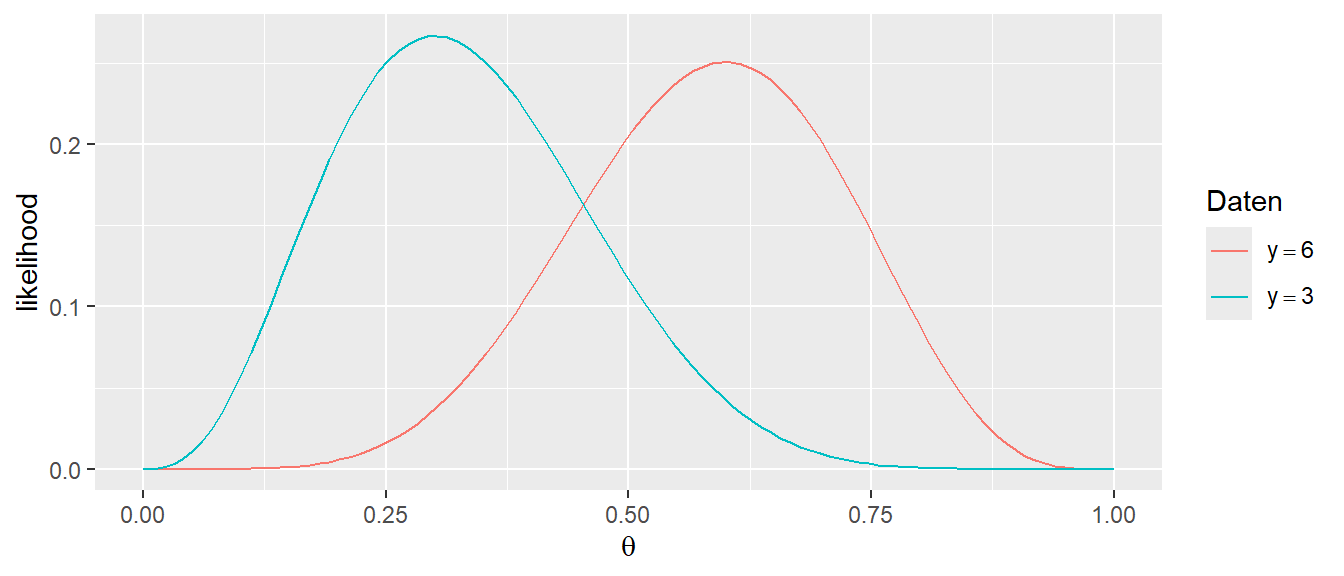
In Abbildung 17.3 ist zu sehen, dass sich die Form der Likelihood-Funktion \(\mathcal{L}(\theta)\) mit den Daten verändert hat. D.h. die Ausprägung des Likelihood-Graphen ist immer von den beobachteten und als gegeben angenommen Daten \(Y\) abhängig. Die zentrale Einsicht ist aber immer, noch, dass die ursprüngliche Dichte- bzw. Wahrscheinlichkeitsfunktion als eine Funktion eines Modellparameters interpretiert werden, während die beobachteten Daten als fixiert angesehen werden. Insgesamt kann nun eine Definition für die Likelihood gegeben werden:
Definition 17.1 (Likelihood ) Seien \(X\) die beobachtete Daten und \(\theta\) ein unbekannter Parameter eines statistischen Modells. Die Likelihood-Funktion \(\mathcal{L}(\theta)\) ist die Wahrscheinlichkeit (bzw. Dichte) der beobachteten Daten, aufgefasst als Funktion des Parameters \(\theta\):
\[\begin{align*} \mathcal{L}(\theta) &= P(\theta \mid X = x) \quad \text{diskrete Verteilung} \\ \mathcal{L}(\theta) &= f_X(\theta \mid X = x) \quad \text{kontinuierliche Verteilung} \end{align*}\]
Die Daten \(X\) werden als fixiert betrachtet, während der Parameter \(\theta\) variiert. Die Likelihood \(\mathcal{L}\) misst, wie plausibel verschiedene Parameterwerte \(\theta\), für die gegeben Daten \(X\), sind.
Eine wichtige Eigenschaft der Likelihood ist, dass es sich nicht um Wahrscheinlichkeitsverteilung handelt. Das Integral \(\int \mathcal{L}(\theta)d\theta\) ist nicht \(1\) wie es für eine Dichtefunktion notwendig wäre.
Nun stellt sich daher die Frage wofür die Likelihood-Funktion \(\mathcal{L}(\theta)\) überhaupt nützlich ist. Die Antwort ist, dass sich mit Hilfe der Likelihood-Funktion Vergleiche anstellen lassen, wie plausibel verschiedene Wert für \(\theta\) unter den beobachteten Daten sind. \(\mathcal{L}(\theta)\) ermöglicht es, denjenigen Parameterwert zu bestimmen, für den die Wahrscheinlichkeit der beobachteten Daten maximal wird. In Abbildung 17.1 zeigt \(\mathcal{L}(\theta)\) ein Maximum für \(p \equiv \theta = 0.6\). Dagegen ist im zweiten Beispiel in Abbildung 17.2 das Maximum bei \(\theta = 0.3\). Das Maximum von \(\mathcal{L}(\theta)\) kann nun als derjenige Wert von \(\theta\) interpretiert werden, der unter den beobachteten Daten als plausibelsten erscheint. D.h. die Frage nach dem Besten Modellparameterwert, wird nun eine Optimierungsaufgabe für die Likelihood-Funktion \(\mathcal{L}(\theta)\). Die Likelihood-Funktion wird verwendet um einen Schätzer für den Modellparameter \(\theta\) zu erhalten. Unter dieser Betrachungsweise wird damit auch das Konzept des Maximum Likelihood-Schätzers einsehbar.
Definition 17.2 (Maximum-Likelihood (ML) ) Seien \(x\) die beobachteten Daten und \(\theta\) ein unbekannter Parameter eines statistischen Modells mit Likelihood-Funktion \(\mathcal{L}(\theta)\). Der Maximum-Likelihood-Schätzer (ML-Schätzer, MLE) ist derjenige Parameterwert \(\hat{\theta}\), der die Likelihood maximiert:
\[ \hat{\theta} = \arg\max_{\theta} \mathcal{L}(\theta). \]
Das heißt: Der Maximum-Likelihood-Schätzer ist der Parameterwert, unter dem die beobachteten Daten am wahrscheinlichsten sind.
Sei nun wieder das Beispiel der Binomialverteilung gegeben und es wurden bei \(N = 10\) insgesamt sechsmal Kopf (\(y = 6\)) beobachtet. Angewendet auf Gleichung 11.4 ergibt sich somit.
\[ \mathcal{L}(\theta) = \binom{10}{6}\theta^6 (1-\theta)^{10-6} = \binom{10}{6}\theta^6(1-\theta)^4 \]
Für diese Funktion soll nun das Maximum bestimmt werden. Allerdings ist das direkte Maximieren der Likelihood-Funktion rechnerisch oft aufwendig. Um sich dies zu vereinfachen wird ein mathematischer Trick angewendet. Es ist möglich unter bestimmten Voraussetzungen, die die Logarithmusfunktion erfüllt (siehe Anhang A), das Maximum einer Funktion \(f(x)\) bzw. im vorliegenden Fall \(\mathcal{L}(\theta)\) zu bestimmen nachdem die Logarithmusfunktion \(log(x)\) auf \(f(x)\) angewendet wurde. D.h. es wird eine neue Funktion \(log(f(x))\) verwendet. Dies wird gemacht, da der Logarithmus, nach den Rechenregeln \(\log(a\cdot b) = \log(a) + \log(b)\) aus der Multiplikation eine Addition macht. Angewendet auf die Likelihood-Funktion resultiert daraus der Loglikelihood \(\ell(\theta) = \log \mathcal{L}(\theta)\).
Angewendet auf den vorliegenden Fall führt dieser Ansatz zu unter Beachtung einer weiteren Rechenregel für den Logarithmus \(\log(a^b) = b\log(a)\):
\[\begin{align*} \ell(\theta) &= \log \mathcal{L}(\theta) \\ &= \log\left(\binom{10}{6}\cdot \theta^6 \cdot (1-\theta)^{4}\right) \\ &= \log\left(\binom{10}{6}\right) + \log\left(\theta^6\right) + \log\left((1-\theta)^{4}\right) \\ &= \log \binom{10}{6} + 6 \log(\theta) + 4\log(1-p) \end{align*}\]
Um nun das Maximum dieser Funktion zu bestimmen, muss die Ableitung berechnet werden und gleich Null gesetzt werden. Bei der Berechnung der Ableitung kann der erste Term direkt gestrichen werden, da es sich um eine Konstante handelt, deren Ableitung gleich Null ist. Dadurch erhält man die Gleichung unter Beachtung das \(\frac{d \log(x)}{dx} = \frac{1}{x}\) und der Kettenregel (siehe Anhang A):
\[ \frac{d \ell{\theta}}{d\theta} = \frac{6}{\theta} - \frac{4}{1-p} = 0. \]
Durch Umformen folgt daraus:
\[ \hat{\theta} = \frac{6}{10}. \]
Dieses Ergebnis sollte intuitiv auch nachvollziehbar sein, wenn bei \(N = 10\) Münzwürfen sechsmal Kopf beobachtet wurde, dann ist der beste Schätzer wohl \(\hat{p} = \hat{\theta} = \frac{y}{N}\). Der Maximum-Likelihood-Schätzer für die Erfolgswahrscheinlichkeit \(p\) ist also der Anteil der beobachteten Erfolge an der Gesamtzahl der Versuche und entspricht genau der relativen Häufigkeit der Erfolge. Die Maximum-Likelihood-Methode liefert in diesem Fall also ein Ergebnis, das sehr gut mit unserer intuitiven Vorstellung übereinstimmt.
Im Zuge der theoretischen Verteilungen wird die Dichtefunktion betrachtet. Für eine gegebene Zufallsvariable kann die Dichte für einen gegebenen Wert, z.B. \(y_i\), über die Dichtefunktion berechnet werden. Wenn eine Zufallsvariable \(X\) einer Normalverteilung folgt, wird die Verteilung von \(X\) mittels der bekannten Dichtefunktion der Normalverteilung beschrieben:
\[\begin{equation*} f(X|\mu,\sigma^2) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2}\frac{(X - \mu)^2}{\sigma^2}\right) \end{equation*}\]
Hier wird die Dichte von \(X\) als eine Funktion von \(\mu\) und \(\sigma^2\) aufgefasst. Das bedeutet, die Werte für \(\mu\) und \(\sigma\) müssen vorgegeben sein, da diese benötigt werden, um die Dichte zu berechnen.
Für die Likelihood erfolgt nun wieder der Perspektivwechsel. Die Zufallsvariable \(X\) wird als gegeben angesehen und die Dichte für verschiedene Werte von \(\mu\) und \(\sigma^2\) abzutragen. Der Einfachheit halber wird angenommen, dass \(\sigma^2\) ebenfalls bekannt und konstant ist. Die Problemstellung ist nun, analog zu dem Binomialbeispiel, einen Wert für \(\mu\) zu ermitteln der am plausibelsten ist. Dazu können nun wieder verschiedene Dichtewerte für ein gegebenes \(x\) in Abhängigkeit von \(\mu\) darstellen, also die Likelihood.
\[ \mathcal{L}(\mu) = f(\mu|x,\sigma^2) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2}\frac{(X - \mu)^2}{\sigma^2}\right) \]
Das Maximum dieser Funktion stellt dementsprechend wieder den Maximumlikelihood-Wert dar und ist derjenige Wert der am plausibelsten ist.
Sei der Wert \(x = 3\) beobachtet, und es ist bekannt, dass \(\sigma = 1\) ist. Natürlich reicht ein einzelner Wert nicht aus, um definitive Aussagen zu treffen, aber das Prinzip soll verdeutlicht werden. Eine Tabelle wird erstellt, die verschiedene Werte von \(\mu_i = [0,1,2,3,4,5,6]\) enthält und die Likelihood \(\mathcal{L}(\mu) = f(\mu|x=3,\sigma^2=1)\) für jeden dieser Werte berechnet (siehe Tabelle 17.1).
| \(\mu\) | Dichte |
|---|---|
| 0 | 0.004 |
| 1 | 0.054 |
| 2 | 0.242 |
| 3 | 0.399 |
| 4 | 0.242 |
| 5 | 0.054 |
| 6 | 0.004 |
Beim Betrachten der Werte in Tabelle 17.1 zeigt sich, dass der Wert bei \(\mu = 3\) die größte Dichte aufweist. Um dies weiter zu verdeutlichen, wird das Ganze als kontinuierlicher Graph dargestellt (siehe Abbildung 17.4)
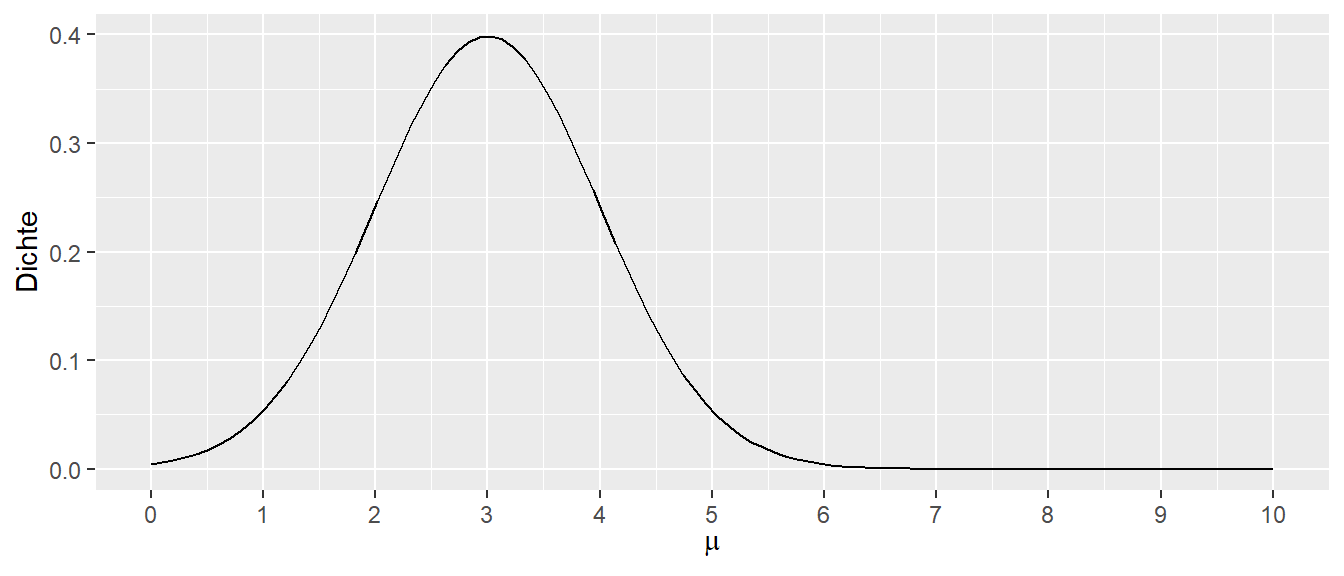
In Abbildung 17.4 ist zu erkennen, dass das Maximum der Likelihood-Funktion beim Wert \(\mu = 3\) liegt. Die Normalverteilung mit \(\mathcal{N}(\mu=3, \sigma=1)\) ist diejenige, die die höchste Dichte produziert und daher auch die höchste Likelihood hat, den beobachteten Wert zu erzeugen. Dies ist intuitiv nachvollziehbar: Wenn ein Wert aus einer Normalverteilung stammt und nur ein einziger Wert vorliegt, macht es Sinn, diejenige Normalverteilung mit dem Mittelwert \(\mu\) zu wählen, die an der Stelle des beobachteten Werts liegt.
Sei diese Beispiel erweitert: Es werden zwei Werte \(x_1 = 1\) und \(x_2 = 2\) beobachtet. Es wird angenommen, dass beide Werte unabhängig voneinander sind und aus der gleichen Normalverteilung stammen. Dadurch das die Wert unabhängig voneinander sind, die Dichten für die beiden Werte miteinander multipliziert werden. Analog wie bei zwei Münzwürfen, die Wahrscheinlichkeit Kopf für beide Münzen zu beobachten ist \(P(KK) = \frac{1}{2}\cdot \frac{1}{2} = \frac{1}{4}\). Die Likelihood-Funktion \(\mathcal{L}\) folgt dementsprechend:
\[\begin{equation*} \mathcal{L} = f(\mu|x_1,\sigma) \cdot f(\mu|x_2,\sigma) \end{equation*}\]
Ein Graph von \(\mathcal{L}\) für verschiedene \(\mu\) bei gegebenem \(\sigma = 1\) hat die folgende Form (Abbildung 17.5).
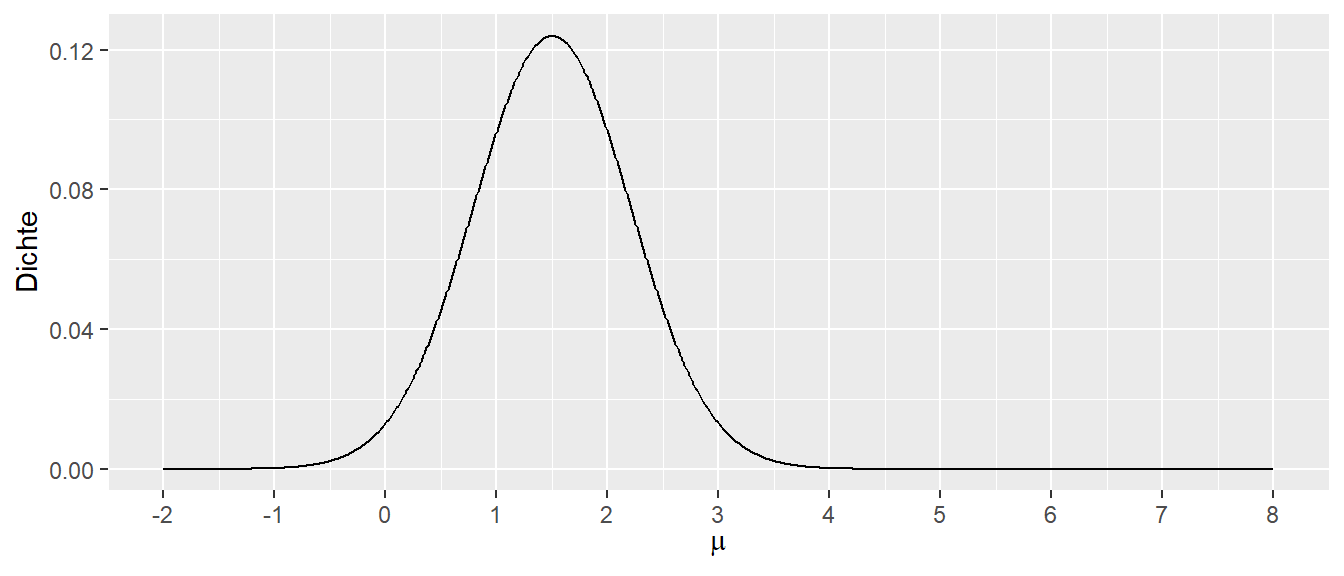
In Abbildung 17.5 liegt das Maximum von \(L\) bei \(\mu = 1.5\), was dem Mittelwert \(\bar{x} = \frac{1}{2}\sum_{i=1}^2 x_i\) entspricht. Intuitiv ist dies nachvollziehbar: Wenn beiden Werten die gleiche Bedeutung zugemessen wird, liegt die Verteilung, die genau in der Mitte zwischen den beiden Werten liegt, am ehesten mit der Erzeugung der beiden Werte im Einklang.
Die Berechnung führt zum gleichen Ergebnis. Es wird wieder der Loglikelihood \(\log\mathcal{L}\) verwendet und der Konsistenz wegen wird das Symbol \(\mu\) durch das Symbol \(\theta\) ersetzt und \(\sigma^2=1, x_1=1, x_2=2\).
\[ \begin{align*} \log\mathcal{L}(\theta) &= \log\left( \frac{1}{\sqrt{2\pi}}\exp\left(-\frac{1}{2}(1-\theta)^2\right)\frac{1}{\sqrt{2\pi}}\exp\left(-\frac{1}{2}(2-\theta)^2\right)\right) \\ &= \log\left( \left(\frac{1}{\sqrt{2\pi}}\right)^2\exp\left(-\frac{1}{2}(1-\theta)^2\right)\exp\left(-\frac{1}{2}(2-\theta)^2\right)\right) \\ &= \log\left( \left(\frac{1}{\sqrt{2\pi}}\right)^2\exp\left(-\frac{1}{2}(1-\theta)^2 -\frac{1}{2}(2-\theta)^2\right)\right) \\ &= 2 \log\left(\frac{1}{\sqrt{2\pi}}\right) - \frac{1}{2}(1-\theta)^2 -\frac{1}{2}(2-\theta)^2 \end{align*} \]
Dieser Ausdruck wird nun wieder nach \(\frac{d}{d\theta}\) abgeleitet wobei der erste Term verschwindet und es folgt.
\[ \begin{align*} \frac{d}{d\theta}\ell(\theta) &= \frac{d}{d\theta}\left( - \frac{1}{2}(1-\theta)^2 -\frac{1}{2}(2-\theta)^2\right) \\ &= \frac{d}{d\theta}\left( - \frac{1}{2}(1-\theta)^2\right) + \frac{d}{d\theta}\left(-\frac{1}{2}(2-\theta)^2\right) \\ &= -\frac{1}{2}\cdot 2(1-\theta) \cdot(-1) -\frac{1}{2}\cdot 2(2-\theta)\cdot (-1) \\ &= (1-\theta) + (2-\theta) \\ &= 3-2\theta \\ \end{align*} \]
Durch Nullsetzen folgt:
\[ 3-2\theta = 0 \Leftrightarrow \theta = \frac{3}{2} = 1.5 \]
D.h. mit \(\theta = \mu\) wurde über die Maximumlikelihood-Methode der gleiche Wert erhalten, welcher auch intuitive am meisten Sinn macht. Allgemein wird also für die Anwendung der Maximumlikelihood-Methode immer ein theoretisches, statistisches Modell benötigt und es wird der plausibelste Modellparameterwert \(\theta\) anhand des Modells bestimmt. Dieser Wert ist dann der Maximumlikelihood-Schätzer \(\hat{\theta}\).
Beispiel 17.1 (Exponentialverteilung) Es sei das folgende Problem betrachtet. Ein Hersteller von LED-Glühbirnen ist daran interessiert die Lebensdauer (in Jahren) der produzierten Birnen zu bestimmen. Eine Verteilung die bei der Modellierung von Zeitspannen verwendet wird, ist die Exponentialverteilung. Die Dichtefunktion der Exponentialverteilung hat einen Parameter \(\lambda\) und die Form:
\[ f_{\lambda}(x) = \begin{cases} \lambda e^{-\lambda x} & x \geq 0 \\ 0 & x < 0 \end{cases} \tag{17.1}\]
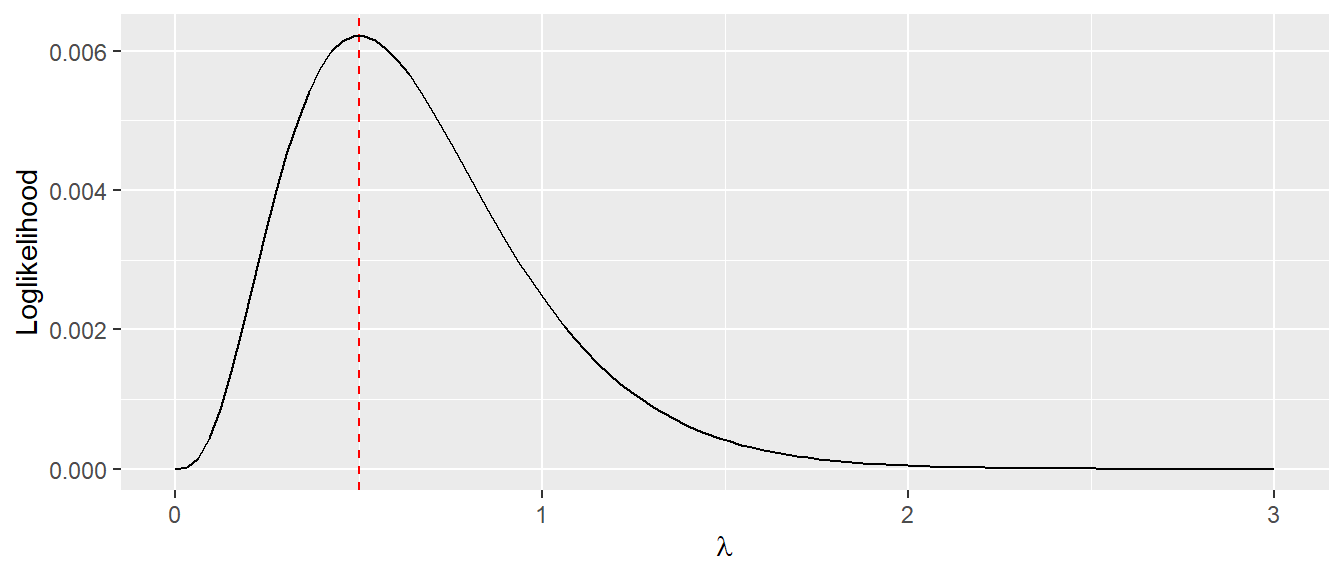
In Abbildung 17.6 sind Exponentialverteilungen für \(\lambda=0.5, 1, 2\) abgetragen. Der y-Achsenabschnitt ist offenbar immer der \(\lambda\)-Wert.

Der Erwartungswert der Exponentialverteilung ist \(E[X]=\frac{1}{\lambda}\) was auch die Standardabweichung \(\sigma_{\lambda} = \frac{1}{\lambda}\) ist.
Um nun die Lebenszeit der Glühbirnen zu bestimmen, wurden drei Glühbirnen \(x_1, x_2, x_3\) bis zum Versagen beobachtet. Per Konstruktion ist die Lebensdauer der drei Birnen unabhängig voneinander. Daher können die Likelihoods der drei Birnen miteinander multipliziert werden. Formal folgt daher mit Gleichung 17.1:
\[ \begin{align*} \mathcal{L}(\lambda \mid x_1, x_2, x_3) &= (\lambda e^{-\lambda x_1)}\cdot (\lambda e^{-\lambda x_2})\cdot (\lambda e^{-\lambda x_3}) \\ &= \lambda^3 e^{-\lambda(x_1 + x_2 + x_3)} \end{align*} \]
Seien nun die folgenden Werte beobachtet worden:
\[ x_1=2, x_2=3, x_3=1 \]
Daraus folgt:
\[ \mathcal{L}(\lambda\mid x_1=2, x_2=3,x_3=1) = \lambda^3e^{-\lambda6} \]
Unter Anwendung des natürlichen Logarithmus folgt:
\[ \begin{align*} \ell(\lambda) &= \log(\lambda^3 e^{-6\lambda}) \\ &= \log(\lambda^3) + \log(e^{-6\lambda}) \\ &= 3\log(\lambda) -6\lambda \end{align*} \]
Ableiten und Nullsetzen führt zu.
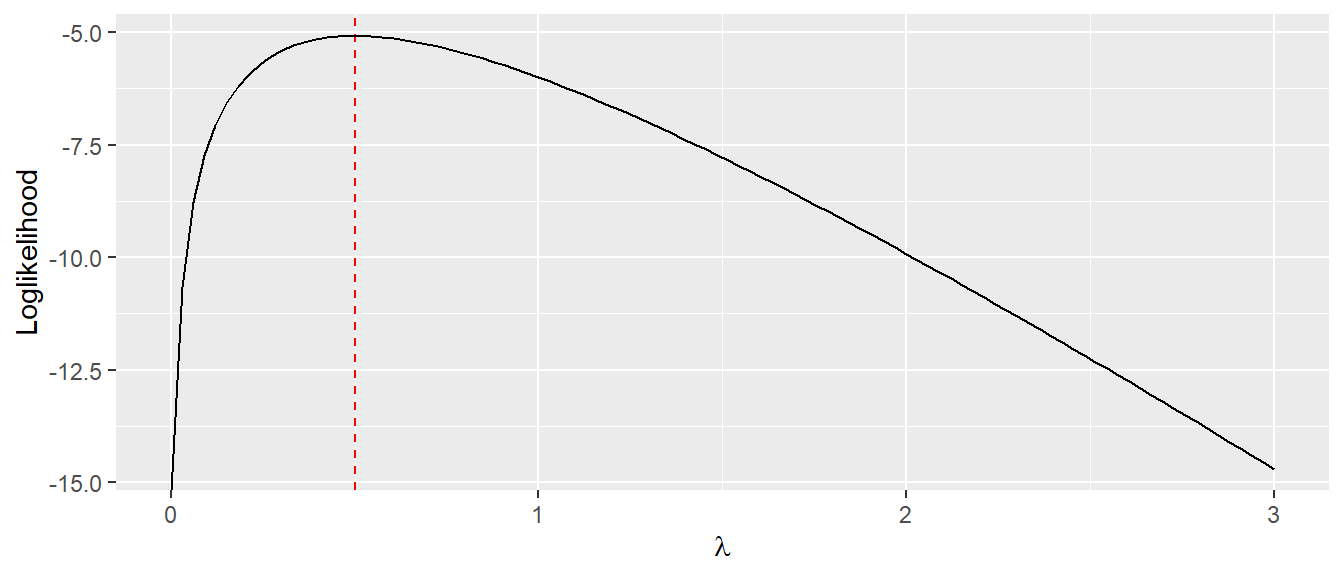
\[ \frac{d}{d\lambda}\ell(\lambda) = \frac{3}{\lambda} - 6 = 0 \Rightarrow \hat{\lambda} = \frac{1}{2} \]
Dementsprechend liegt die mittlere Lebensdauer der Glühbirnen aus dem Betrieb bei zwei Jahren.
In Abbildung 17.7 sind die Graphen Likelihood und Likelihoodfunktion abgetragen.
Beispiel 17.2 (MLE von \(\mu\) bei der Normalverteilung bei allgemeinem \(N\)) Im folgenden wird der Schätzer für den Parameter \(\mu\) bei der Normalverteilung \(\mathcal{N}(\mu,\sigma^2)\) für allgemeines \(N\) hergeleitet. Seien als \(N\) Datenwerte aus der \(\mathcal{N}(\mu, \sigma^2)\) beobachtet werden und es soll anhand der Wert der Populationsparameter \(\mu\) mittels MLE bestimmt werden.
Die beobachteten Werte sind unabhängig voneinander und stammen aus der gleichen Verteilung (unabhängig und gleichverteilt = [engl] independently and identically distributed IID). Jeder indiviudelle Wert \(X_i\) folgt der Verteilung:
\[ f_{X_i}(x_i) = \frac{1}{2\pi\sigma^2}e^{-\frac{(x_i - \mu)^2}{2\sigma^2}} \]
Da die Werte IID sind, können für den Likelihood die individuellen Dichten miteinander multipliziert werden.
\[ \begin{align*} \mathcal{L}(\mu,\sigma^2\mid x_1,\ldots,x_N) &= \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x_1 - \mu)^2}{2\sigma^2}} \cdots \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x_N - \mu)^2}{2\sigma^2}} \\ & = \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^Ne^{-\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2}} \end{align*} \]
Wiederum Anwendung der Logarithmusfunktion führt zu:
\[ \begin{align*} \ell(\mu,\sigma^2|x1,\ldots,x_N) &= \log\left(\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^N\cdot e^{-\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2}}\right) \\ &= \log\left(\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^N\right) + \log\left(e^{-\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2}}\right) \\ &= N \log\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right) -\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2} \\ &= -N \log\left(\sqrt{2\pi\sigma^2}\right) -\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2} \\ \end{align*} \]
Die Loglikelihood-Funktion hat zwei Parameter \(\mu\) und \(\sigma\) von denen hier nur der MLE für \(\mu\) bestimmt werden soll. Daher wird die Loglikelihood-Funktion partiell nach \(\mu\) abgeleitet und gleich Null gesetzt.
\[ \frac{\partial}{\partial\mu} \ell(\mu,\sigma^2|x1,\ldots,x_N) = \frac{\partial}{\partial\mu}\left( -N \log\left(\sqrt{2\pi\sigma^2}\right) -\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2}\right) \]
Der erste Term ist nur von \(\sigma\) abhängig und wird daher unter der partiellen Ableitung als Konstante behandelt. Dementsprechend wird der erste Term gleich NULL.
\[ \begin{align*} \frac{\partial}{\partial\mu} \ell(\mu,\sigma^2|x1,\ldots,x_N) &= \frac{\partial}{\partial\mu}\left(-\sum_{i=1}^N\frac{(x_i - \mu)^2}{2\sigma^2}\right) \\ &= -\frac{1}{2\sigma^2}\sum_{i=1}^N\frac{\partial}{\partial\mu}(x_i - \mu)^2 \\ &= -\frac{1}{2\sigma^2}\sum_{i=1}^N 2(x_i - \mu)\cdot(-1) \\ &= \frac{2}{2\sigma^2}\sum_{i=1}^N (x_i - \mu) \\ &= \frac{1}{\sigma^2}\sum_{i=1}^N (x_i - \mu) \\ \end{align*} \]
Dieser Term wird nun gleich Null gesetzt und es folgt:
\[ \begin{align*} \frac{1}{\sigma^2}\sum_{i=1}^N (x_i - \mu) &= 0 \\ \sum_{i=1}^N x_i - \sum_{i=1}^N\mu &= 0 \\ \sum_{i=1}^N x_i - N\mu &= 0 \\ \sum_{i=1}^N x_i &= N\mu \\ \hat{\mu} &= \frac{1}{N}\sum_{i=1}^N x_i = \bar{x} \\ \end{align*} \]
Dies zeigt, das der MLE-Schätzer für den Populationsparameter \(\mu\) von \(N\) Beobachtungen aus einer Normalverteilung \(\mathcal{N}(\mu,\sigma^2)\) der Mittelwert \(\bar{X}\) ist, wie das schon vorher gezeigt wurde und auch intuitiv sinnvoll erscheint.
Beispiel 17.3 (Mischverteilung) Sei nun noch ein Beispiel betrachtet, bei dem die Lösung nicht schon ein bekannter Schätzer ist. Es seien die folgenden Daten betrachtet worden. Einmal drei Werte $x_i , i = 1,2,3 $ von denen ausgegangen wird, dass sie aus einer Normalverteilung \(\mathcal{N}(\mu, \sigma_1)\) stammen und zwei Werte \(x_i \in [20, 22], i = 4,5\), die aus einer Normalverteilung \(\mathcal{N}(\mu, \sigma_2)\) stammen. D.h. die Daten stammen aus zwei verschiedenen Normalverteilungen mit unterschiedlichen Standardabweichungen \(\sigma_1\) und \(\sigma_2\). Beide Verteilungen haben aber den gleichen Mittelwert \(\mu\). Ein mögliches Beispiel wären zwei Traningsgruppen die zwar im Mittel die gleiche Leistung erbringen aber die Leistung in Gruppe 2 streuen stärker als diejenigen von Gruppe 1. Seien \(\sigma_1 = 1\) und \(\sigma_2 = 2\) bekannt. Es soll nun graphisch der Maximum-Likelihood Schätzer für \(\mu\) graphisch mittels eines kurzen R-Programms ermittelt werden. Zunächst alle Werte die gegeben sind.
sigma_1 <- 1
sigma_2 <- 2
x_1 <- c(10, 13, 15)
x_2 <- c(20, 22)Nun muss eine Likelihood-Funktion \(\mathcal{L}(\theta)\) definiert werden. \(\theta\) ist in diesem Fall \(\mu\). Die Daten sind wieder unabhängig voneinander, d.h. die Dichten können miteinander multipliziert werden. Für die ersten drei Werte ist die Likelihood die Dichtefunktion der Normalverteilung mit \(\mathcal{N}(\theta, \sigma_1 = 1)\), während für die Werte \(4\) und \(5\) die Likelihood-Funktion die Normalverteilung mit \(\mathcal{N}(\theta, \sigma_2=2)\) ist Entsprechend ergibt sich:
lik <- function(mu) {
prod(dnorm(x_1, mu, sigma_1)) * prod(dnorm(x_2, mu, sigma_2))
}Nun kann der Maximum-Likelihood Schätzer für \(\hat{\theta}\) bestimmt werden. Da die Werte zwischen \(10\) und \(22\) liegen, kann der Mittelwert auch nur dort liegen und entsprechend werden nur Werte in diesem Bereich zur Probe für \(\theta\) verwendet.
theta_s <- seq(10, 22, length=200)
lik_theta <- purrr::map_dbl(theta_s, lik)Für den Graphen der \(\theta\)s gegen den Likelihood ergibt sich entsprechend:
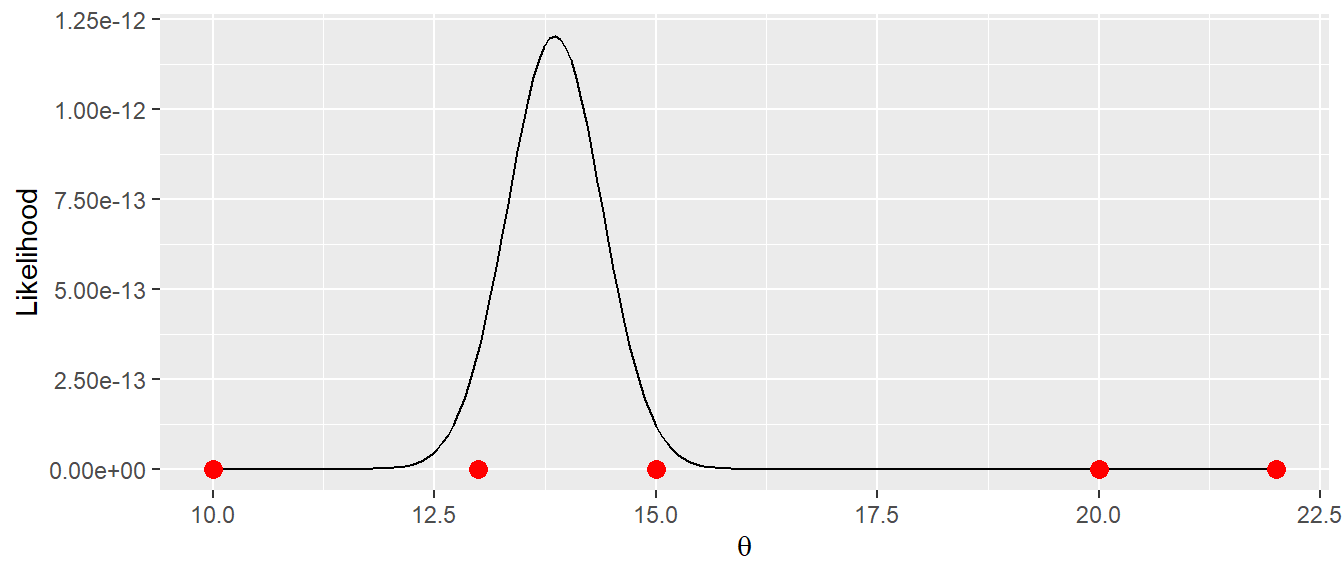
Das Maximum befindet sich bei:
theta_s[which.max(lik_theta)][1] 13.8593D.h. der Maximum-Likelhood Schätzer für die Mischverteilung liegt bei \(\hat{\theta} = \hat{\mu} = 13.86\). Tatsächlich lässt sich zeigen, dass für dieses einfache Beispiel auch wieder eine geschlossene Lösung gefunden werden kann. Mittels Ableitung von \(\mathcal{L}(\theta)\) und Nullsetzen folgt:
\[ \hat{\theta} = \frac{\frac{n_1}{\sigma_1^2}\cdot \bar{x}_1 + \frac{n_2}{\sigma_2^2}\cdot\bar{x}_2}{\frac{n_1}{\sigma_1^2} + \frac{n_2}{\sigma_2^2}} \]
D.h. der Mittelwert \(\mu\) der Mischverteilung ist ein Mittelwert aus den beiden unterliegenden Verteilung der Anhand der Stichprobengröße und der Varianz gewichtet wird. Dabei wird \(\hat{\mu}\) mit größerwerdender Stichrpobe und kleiner werden Varianz zu dem jeweiligen Mittelwert gezogen. Dies wird auch in Abbildung 17.8 deutlich, wo der Hochpunkt deutlich näher an den kleineren Werten aus \(x_1\) (links) liegt als an den Werte von \(x_2\), da die Stichprobe für \(x_1\) größer ist und auch die Varianz bzw. die Standardabweichung \(\sigma_1 = 1\) kleiner ist. Im vorliegenden Fall führt die Berechnung tatsächlich dann auch zu:
\[ \hat{\theta}_{\text{geschlossen}} = \frac{\frac{3}{1}\cdot 12.\bar{6} + \frac{2}{2}\cdot21}{\frac{3}{1}+\frac{2}{2}} = 13.86 \]
D.h. es resultiert der gleiche Wert für \(\hat{\theta}\) der mittels Maxmum-Likelihood ermittelt wird. Insgesamt sollte dieses Beispiel aber wieder zeigen, wie mittels der Maximum-Likelihood Schätzung ein Schätzer für einen Modellparameter in einem statistischen Modell ermittelt werden kann.
17.2 Maximum-likelihood Methode bei der einfachen linearen Regression
Dieser Ansatz lässt sich auch auf das Modell der einfachen linearen Regression anwenden. Bei der einfachen linearen Regression wird angenommen, dass die \(Y\)-Werte für jeden \(X\)-Wert einer Normalverteilung mit einer Varianz \(\sigma^2\) folgen. Formal:
\[ Y_i = \mathcal{N}(\beta_0 + \beta_1 X_i, \sigma^2) \tag{17.2}\]
Für einen einzelnen Wert bedeutet dies nun für die Likelihood-Funktion \(\mathcal{L}\):
\[ \mathcal{L}(\beta_0, \beta_1, \sigma^2|y_i) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2\sigma^2}\right) \tag{17.3}\]
In diesem Fall ist also \(\theta\) nicht ein einzelnen Wert sondern ein Vektor \(\theta = (\beta_0, \beta_1, \sigma^2)\). Mit einem einzelnen Wert lässt sich \(\theta\) nicht bestimmen, da wird nach Ableitung drei Gleichung mit drei Unbekannten erhalten würden, die nicht gelöst werden können. Nun kommt die nächste Annahme zum tragen, nämlich das bei mehreren Werten diesen unabhängig voneinander sind. Dann können die individuellen Likelihoods miteinander multipliziert werden.Dies führt zu einer Gesamt-Likelihood-Funktion \(\mathcal{L}\) in der folgenden Form:
\[ \begin{aligned} L(\beta_0, \beta_1, \sigma^2\mid x_i, y_i) &= \prod_{i=1}^{N} f(\beta_0, \beta_1, \sigma^2\mid x_i, y_i) \\ &= \prod_{i=1}^{N} \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2\sigma^2}\right) \end{aligned} \]
Durch Anwendung der Rechenregel \(e^a e^b = e^{a+b}\) kann die Formel vereinfacht werden:
\[ \begin{aligned} \mathcal{L}(\beta_0, \beta_1, \sigma^2|y_i) &= \left(\frac{1}{\sqrt{2\pi \sigma^2}}\right)^N \exp\left(-\frac{\sum_{i=1}^N (y_i - \beta_0 - \beta_1 x_i)^2}{2 \sigma^2}\right) \\ &= \left(\frac{1}{2\pi \sigma^2}\right)^{N/2} \exp\left(-\frac{\sum_{i=1}^N (y_i - \beta_0 - \beta_1 x_i)^2}{2 \sigma^2}\right) \end{aligned} \]
Das Maximum von \(\mathcal{L}\) wird wie immer gefunden, indem die Likelihoodfunktion abgeleitet und gleich Null gesetzt wird. Um die Berechnungen zu vereinfachen, wird wieder der Logarithmus der Likelihood-Funktion verwendet. Die Loglikelihood \(\ell(\beta_0, \beta_1, \sigma^2\) ergibt die folgende Funktion:
\[ \begin{align*} \ell(\beta_0, \beta_1, \sigma^2) &= \ln \mathcal{L}(\beta_0, \beta_1, \sigma^2) \\ &= \ln \left[\left(\frac{1}{2\pi \sigma^2}\right)^{N/2} \exp\left(-\sum_{i=1}^N \frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2 \sigma^2}\right)\right] \\ &= \ln \left[\left(\frac{1}{2\pi \sigma^2}\right)^{N/2} \right] + \ln \left[\exp\left(-\sum_{i=1}^N \frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2 \sigma^2}\right)\right] \\ &= \frac{N}{2} \ln \left[\left(\frac{1}{2\pi \sigma^2}\right) \right] -\sum_{i=1}^N \frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2 \sigma^2} \\ &= -\frac{N}{2}\ln(2\pi\cdot\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^{N}(y_i - \beta_0 - \beta_1 x_i)^2 \\ &= -\frac{N}{2}\ln(2\pi) - \frac{N}{2}\ln(\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^{N}(y_i - \beta_0 - \beta_1 x_i)^2 \end{align*} \]
Durch partielle Ableitung der Funktion \(\ell(\beta_0, \beta_1, \sigma^2)\) nach \(\beta_0\) und \(\beta_1\) und anschließendes Nullsetzen ergibt sich das gleiche Gleichungssystem wie bei den vorherigen Herleitungen durch Minimierung der quadrierten Abweichungen, d.h. den Normalengleichungen. Beispielsweise ergibt sich für \(\beta_0\):
\[\begin{align*} \frac{\partial \ell(\beta_0, \beta_1, \sigma^2)}{\partial \beta_0} &= \frac{\partial}{\partial \beta_0} \left[-\frac{n}{2}\ln(2\pi) - \frac{n}{2}\ln(\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^{N}(y_i - \beta_0 - \beta_1 x_i)^2\right] \\ &= \frac{2}{2\sigma^2}\sum_{i=1}^N (y_i - \beta_0 - \beta_1 x_i) \end{align*}\]
Wenn dieser Ausdruck gleich Null gesetzt wird, ergibt sich der gleiche Ausdruck wie formal bei den Normalengleichungen für \(\beta_0\):
\[ \begin{alignat}{2} && \frac{2}{2\sigma^2}\sum_{i=1}^N (y_i - \beta_0 - \beta_1 x_i) = 0 \nonumber \\ \Leftrightarrow\mkern40mu && \sum (y_i - \beta_0- \beta_1 x_i) = 0 \nonumber \\ \Leftrightarrow\mkern40mu && \sum y_i - \sum \beta_0- \sum \beta_1 x_i = 0 \nonumber \\ \Leftrightarrow\mkern40mu && n \bar{y} - n \beta_0- \beta_1 n \bar{x} = 0 \nonumber \\ \Leftrightarrow\mkern40mu && \bar{y} - \beta_0- \beta_1 \bar{x} = 0 \nonumber \\ \Leftrightarrow\mkern40mu && \bar{y} - \beta_1 \bar{x} = \beta_0\nonumber \\ \Leftrightarrow\mkern40mu && \hat{\beta}_0= \bar{y} - \beta_1 \bar{x} \end{alignat} \]
Die Herleitung für \(\beta_1\) entspricht ebenfalls derjenigen, die auf Basis der Normalengleichungen (siehe Gleichung 13.5) hergeleitet wurden. Der Unterschied liegt darin, dass bei den Normalengleichungen keine Annahmen über die Verteilung der Werte gemacht wurden. Stattdessen wurde eine Methode gesucht, die die quadrierten Residuen minimiert. Im Gegensatz dazu basiert die Herleitung der Gleichungen durch die Maximum-Likelihood-Methode auf spezifischen Verteilungsannahmen und stellt damit ein allgemeineres Verfahren da. Im Fall der linearen Regression führen beide Methoden zum gleichen Ergebnis. Die Maximum-Likelihood-Methode kann jedoch auch in Fällen angewendet werden, bei denen die Methode der quadrierten Abweichungen nicht funktioniert. Für die Anwendung ist es entscheidend, das zugrunde liegende Prinzip und den Unterschied zwischen den beiden Ansätzen zu verstehen.
17.2.1 Maximum-likelihood bei der einfachen Regression in R mittels numerischer Optimierung
Es folgt ein kleines Beispiel um zu zeigen, wie über die Maximumlikelihood-Methode numerisch die Modellparameter bestimmt werden können. Eine numerische Lösung bietet sich immer dann an, wenn es nicht möglich ist die Parameter über eine geschlossene Lösung zu ermitteln. Es seien \(N = 20\) zufällige Punkte generiert und \(\sigma\) sei bekannt mit \(\sigma=1\). Zwischen \(X\) und \(Y\) sei der Zusammenhang \(Y = 2 + 3x\) gegeben. D.h. der DGP ist vollständig bekannt, aber in einem tatsächlichen Experiment natürlich unbekannt. Ziel ist es jetzt die wahren Steigungskoeffizienten \(\beta_0 = 2\) und \(\beta_1 = 3\) mittels einer Zufallsstichprobe anhand des Maximum-Likelihoods zu bestimmen. Dazu wird in R eine Zufallsstichprobe generiert. Die \(X\)-Wert werden zunächst anhand einer Gleichverteilung bestimmt, anschließend werden die \(Y\)-Wert anhand der Formel berechnet und zufällige Residuen mittels dnorm() generiert.
set.seed(1)
n <- 20
sigma <- 1
x <- runif(20, 3, 7)
y <- 2 + 3*x + rnorm(20, 0, sigma)Als Streudiagramm sehen die Daten wie folgt aus (siehe Abbildung 17.9).
Normalerweise können die Modellparameter direkt mit lm() bestimmt werden.
mod <- lm(y~x)
coef(mod)(Intercept) x
4.134989 2.602081 Der Parameterschätzer sind entsprechend \(\hat{\beta}_0 = 4.1\) bzw. \(\hat{\beta}_1 = 2.6\). Nun soll die Likelihood \(\mathcal{L}(\theta)\) bzw. die Loglikelihood \(\ell(\theta)\) und deren Maximum numerisch bestimmt werden. Dazu muss wieder eine Likelihood-Funktion definiert werden. Dazu wird wieder dnorm() verwendet, da die \(Y\)-Werte für jeden gebenen \(X\)-Wert einer Normalverteilung folgen (siehe Gleichung 17.3). Der Mittelwert der Normalverteilung für ein bestimmtes \(X\) folgt der Geraden, also \(\beta_0 + \beta_1 \cdot X\) (siehe Gleichung 17.2), während \(\sigma^2 = 1\) gegeben ist. Die Funktion bekommt den Bezeichner log_likelihood. Der Parameter von log_likelihood() wird der Konvention folgend mit \(\theta\) bezeichnet und ist ein Vektor mit zwei Einträgen \(\theta = (\beta_0, \beta_1)\).
Für jedes Wertpaar wird nun die Dichte bestimmt indem der jeweilige \(y_i\) Wert als erstes Argument an dnorm() übergeben wird und der dazugehörigen Mittelwert \(\mu\) mittels der Regressionsgleichung \(\beta_0 + \beta_1 * x_i\) berechnet wird. Die Funktion dnorm() hat ein zusätzliches Argument log mit dem angegeben wird, ob der Dichtewert oder der Logarithmus des Dichtewertes zurückgegeben werden soll. Dies ist dem Umstand geschuldet, dass diese Funktion tatsächlich oft dazu benutzt wird den Loglikelihood \(\ell\) zu berechnen. Da dnorm() auch Vektoren verarbeiten kann, werden alle Werte direkt übergeben. dnorm() berechnet den Loglikelihood für jeden Wert und gibt diese in einem Vektor der gleichen Länge zurück. Dieser Vektor muss dann nur aufaddiert werden um den Loglikelihood zu bestimmen.
log_likelihood <- function(theta) {
beta_0 <- theta[1]
beta_1 <- theta[2]
ll <- dnorm(y, beta_0 + beta_1 * x, sigma, log=T)
-sum(ll)
}Um nun, das Maximum dieser Funktion zu finden wird die Funktion optim() verwendet. Diese berechnet für eine übergebene Funktion das Minimum. Daher wird in log_likelihood() die negative Summe -sum(ll) zurück gegeben. Ein Maximum der Funktion \(f(x)\) ist ein Minimum der Funktion \(-f(x)\). Als ersten Parameter benötigt optim() Startwerte für \(\theta\) für die Optimierung. Diese sind auf \(\theta_{\text{Start}} = c(1,2)\) gesetzt worden.
theta_start <- c(1,2)
theta_num <- optim(theta_start, log_likelihood)Der Rückgabewert von optim() hat einen Eintrag par der die gefunden Werte für das Maximum (respektive Minimum) enthält.
theta_num$par[1] 4.135080 2.602148Die Werte der Optimierung stimmen mit denjenigen von coef(mod) überein. Dies zeigt somit auch noch mal, wie mittels der Likelihood-Funktion Modellparameter bestimmt werden können, sobald eine statistisches Modell des DGP vorhanden ist. D.h. dieser Ansatz funktioniert auch für deutlich kompliziertere Modell bei denen eine algebraische Herleitung nicht mehr möglich ist.
17.3 Take-away
- Das Ziel von MLE ist sehr intuitiv: Finde genau die Parameterwerte \(\theta\), die die beobachteten Daten am wahrscheinlichsten machen.
- Die Likelihood ist keine Wahrscheinlichkeit, sondern nur zum Vergleich.
- Meistens wird die \(\log\mathcal{L}\) maximiert. Das Maximieren von \(\log\mathcal{L}\) ist dasselbe wie Maximieren von \(\mathcal{L}\)
- Bei normalverteilten Residuen ist MLE äquivalent zur Methode der kleinsten Quadrate.
- MLE ist sehr allgemein gültig und kann auch bei komplizierteren Fällen angewendet werden. Die Ergebnisse beruhen dann nicht auf einer geschlossen Lösungsgleichung sondern werden über numerische Optimierung ermittelt.
17.4 Zum Weiterlesen
Kurze Einführungen zu MLE sind in Myung (2003) und im Abschnitt in Kapitel 2 in Bishop und Bishop (2023) zu finden. Kapitel 2 aus Roback und Legler (2021) beschäftigt sich ausschließlich mit Maximum Likelihood. Eine komplettes Buch zum Thema ist Rohde (2014).